























Guida AI Skill
Introduzione
In questa guida vorrei presentarvi non solo le skills AI, che sono delle nuove forme di controllo del contesto proposte da Anthropic e ormai diventate uno standard globale anche negli altri ecosistemi, come quello di Google, quello di OpenAI e tanti altri.
Ci troviamo in una situazione in cui esistono modelli con finestre di contesto sempre più ampie che possono elaborare centinai di migliaia di parole alla volta.
Avere una finestra di contesto ampia è sicuramente un parametro da tenere in considerazione.
Però tutti ci dimentichiamo del fenomeno del lost in the middle…
quando forniamo un testo lungo ad un large language model, non tutto viene analizzato con la stessa efficacia.
Esiste una curva, con una pancia decrescente, per cui l’informazione posta a metà tende a perdere rilevanza. Non viene “dimenticata” in senso assoluto, ma le viene data meno importanza. E quindi tutto quello che mettiamo nel mezzo non viene preso in considerazione con la stessa forza.
Se la context window è grande ma non è perfettamente efficace, come facciamo a curare al massimo il contesto che diamo ogni volta ai nostri sistemi di AI?
Dobbiamo tenerlo bene a mente: la qualità delle risposte è determinata dalla qualità del contesto. Di fatti negli ultimi periodi si sente parlare sempre di più di Context Engineering.
Se non diamo il giusto contesto, l’intelligenza artificiale non riesce a capire:
quale strumento deve utilizzare,
quali informazioni deve prendere,
in che modo vogliamo che lavori.
Facciamo un esempio molto pratico!
“Voglio una landing page con un form, una parte iniziale di copy persuasivo e poi una call to action importante.”
Detta così, i LLM non sanno nulla:
Non sa quali sono i nostri colori.
Non sa se vogliamo bottoni arrotondati o con bordo rigido.
Non sa quali regole di margine utilizziamo.
Non sa come organizziamo le informazioni.
Non sa il nostro tone of voice.
Tutto questo dobbiamo darglielo ogni volta.
E una volta che lo abbiamo scritto in chat, quel contesto dove va? Si perde.
Dobbiamo reinserirlo, riformularlo, validarlo di nuovo.
Ed è in questo perimetro che le skills si inseriscono.
Con le skills possiamo introiettare tutto ciò che vogliamo far ricordare per una determinata attività in una struttura stabile.
Una skill non è altro che una cartella.
Dentro quella cartella mettiamo la ricetta per l’intelligenza artificiale. Mettiamo il contesto.
Nel momento in cui utilizziamo l’intelligenza artificiale con delle skills, la arricchiamo di un contesto standardizzabile, riutilizzabile, coerente.
Non è solo memoria. È struttura.
Ora, in questa guida, andremo a vedere cosa sono le skills nel dettaglio, ma soprattutto quali sono i punti davvero importanti da comprendere nel contesto più ampio della narrativa odierna su questi strumenti.
Skills: le basi
In questo capitolo andiamo a capire bene che cosa sono le skills e da cosa sono composte.
Non voglio dilungarmi, perché in realtà è molto semplice.
Stiamo parlando di una cartella, da dare in pasto ai nostri sistemi, che contiene diversi file di contesto.
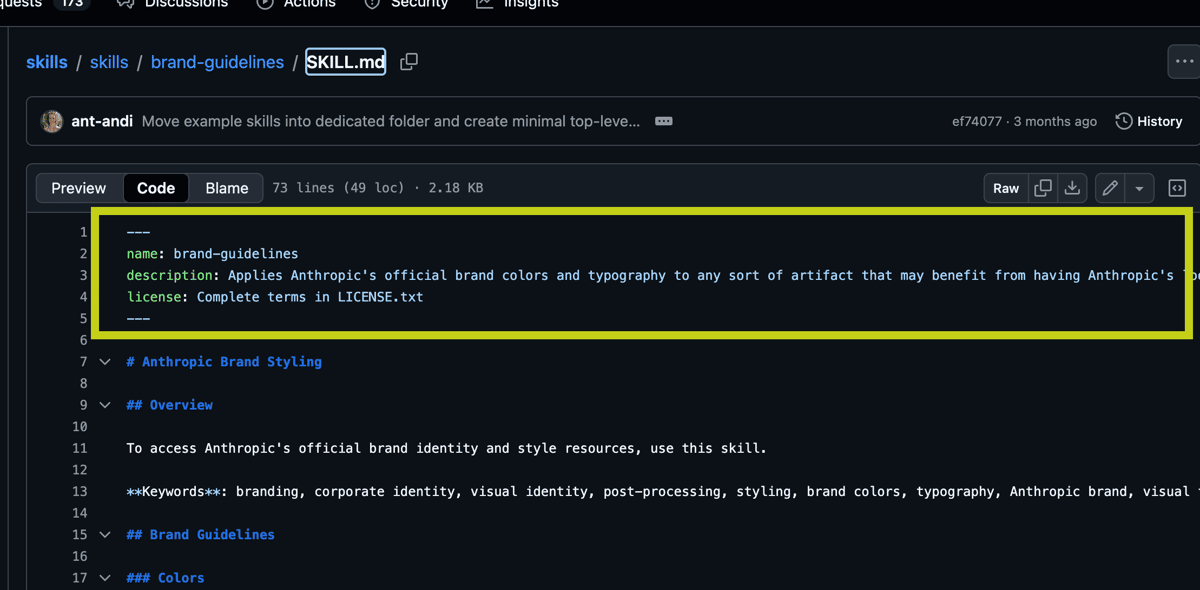
SKILL.md
Il primo file, il più importante, che è lo SKILL.md .
Sono istruzioni in Markdown con uno YAML frontmatter, che serve per definire e dare all’intelligenza artificiale tutte le informazioni necessarie per utilizzare quella skill.
Immaginatela come una ricetta. Una vera e propria ricetta.
💡 Un esempio pratico
Immaginiamo di voler creare una skill che scarica un video YouTube e ne fa un riassunto.
Senza skill, ogni volta dovremmo:
capire come scaricare il video,
magari scrivere o generare uno script,
eseguirlo da terminale,
estrarre l’audio,
trasformarlo in testo con un altro script,
poi chiedere il riassunto.
Ogni volta da zero.
Con una skill, invece, è tutto scritto dentro.
Nel file
SKILL.mdpossiamo dire:
quando l’utente fornisce un link YouTube,
utilizza questo script per scaricare il video,
utilizza quest’altro per estrarre l’audio,
utilizza quest’altro ancora per la trascrizione,
e poi genera il riassunto seguendo queste regole.
L’intelligenza artificiale segue la ricetta, utilizza contestualmente i file necessari e produce il risultato.
Lo SKILL.md è la ricetta.
Ma come ogni ricetta, servono gli ingredienti.
Gli ingredienti della Skill
Oltre allo SKILL.md (obbligatorio), possiamo avere altre cartelle opzionali:
1. scripts/
Se abbiamo già uno script funzionante, non dobbiamo farlo rigenerare ogni volta.
Lo mettiamo nella cartella.
Nel SKILL.md scriviamo:

“Se l’utente chiede di scaricare un video, utilizza lo script presente nella cartella.”
L’intelligenza artificiale leggerà questa istruzione e utilizzerà direttamente quel codice.
2. references/
Qui possiamo mettere documentazione e regole operative.
Ad esempio:
tono di voce,
struttura dei report,
parole da usare o evitare,
linee guida redazionali.
Non deve reinventarle ogni volta. Le trova già lì.
3. assets/
Font, immagini, template, video, audio, qualsiasi risorsa.
Se la skill dice di usare un determinato font, non deve andarlo a cercare.
È già nella cartella.
In sintesi:
SKILL.md→ la ricettascripts / references / assets → gli ingredienti
Quando facciamo spesso qualcosa, possiamo introiettarlo in una skill. E poi riutilizzarlo ovunque: Cloud Code, Claude piattaforma, Codex, Antigravity, altri ambienti.
Le skills sono nate in Anthropic, ma la tecnologia è universale.
Qualsiasi Large Language Model può utilizzare questo paradigma in maniera efficiente.
I principi core del design di una Skill
Il vero cambio di paradigma sta nel sistema a tre livelli che consente ai modelli di avere nel contesto solo le informazioni necessarie ed ottimizzarne la gestione.
Primo livello: YAML frontmatter
Quando carichiamo molte skills in un ambiente, non viene messo tutto nel contesto.
Viene caricato solo lo YAML frontmatter. contenuta neal file skill.md
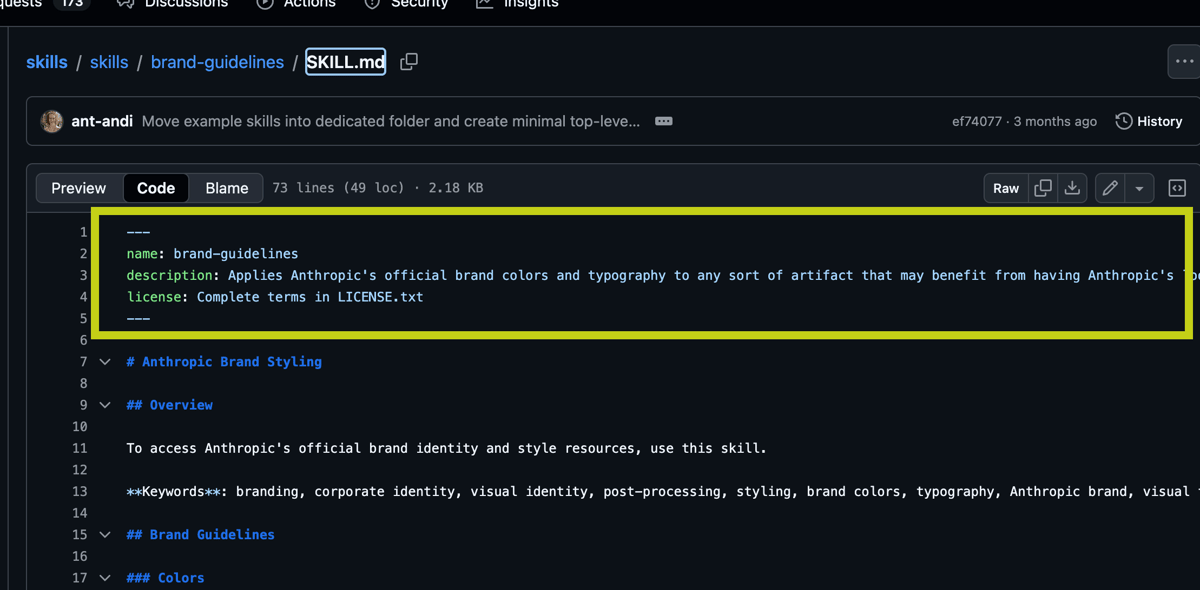
Questa parte contiene:
che cosa fa la skill,
quando deve essere utilizzata.
È estremamente leggero.
Vantaggi:
Non saturiamo la finestra di contesto.
L’AI ha solo il contesto necessario nel momento in cui serve.
Economizziamo token.
Se l’utente dice:
“Scaricami un video YouTube”
Il sistema guarda solo le prime righe di tutte le skill e capisce quale attivare.
Secondo livello: SKILL.md
Una volta scelta la skill, viene caricato tutto il file Markdown.
Ora l’AI ha la ricetta completa.
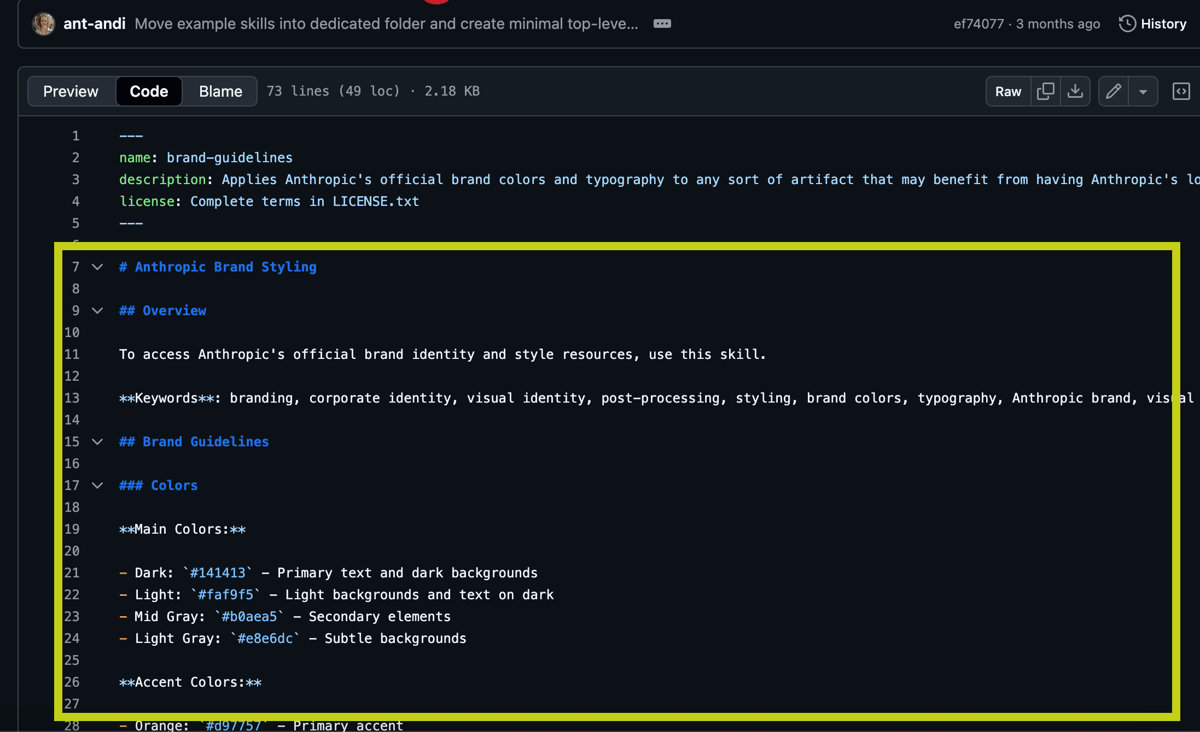
Terzo livello: file collegati
Dalla ricetta capisce che deve utilizzare:
uno script,
un asset,
una reference.
Li carica solo in questo ultimo momento
Non prima. Capite il cambio di paradigma?
Prima: metti tutto nel contesto, lo sporchi, lo saturi, paghi token che non usi.
Adesso: carichi solo ciò che serve, quando serve.
Questo:
migliora le performance,
rende il modello più efficace,
riduce il rischio di degradazione del contesto,
abbassa i costi (ogni token processato è un costo reale).
Skills e MCP
Per concludere questa ultima parte introduttiva è doveroso collegare alle Skills un altra tecnologia che ha rivoluzionato il modo in cui i modelli in intelligenza artificiale si interfacciano con software esterni ottenendo e scrivendo dati.
Dentro una skill possiamo definire come utilizzare strumenti complessi come gli MCP in moda da semplificare e standardizzarne il comportamento.
Ad esempio:
“Se l’utente chiede tutti i task in Notion, utilizza l’MCP in questo modo, facendo queste richieste.”
L’utente non deve sapere nulla di API, payload, chiamate strutturate.
La skill incapsula tutto, ed ecco che anche un non tecnico può orchestrare automazioni complesse.
Qui non stiamo più parlando di usare ChatGPT la domenica, qui diventiamo power user dell’intelligenza artificiale.
E questo è il vero concetto delle skills:
standardizzare il contesto,
modularizzare il sapere operativo,
attivarlo solo quando serve,
trasformare l’AI da strumento generico a sistema strutturato.
Prima di creare una Skill
Try first
Prima di crearne nuove skills, il mio consiglio è quello di provare quelle fatte da altri.
Ci sono molte directory con skill fatte da altre persone.
C’è proprio una dinamica di sharing is caring online, dove possiamo trovare una serie di skills.
Ci sono aziende che propongono le loro skills collegate ai loro servizi. (Non è carità: utilizzi i loro modelli o le loro API a pagamento 😛)
Oppure ci sono persone che non hanno grandi interessi commerciali, ma mettono comunque a disposizione le proprie skill.
Una volta provare ed analizzare skill altrui è il momento di crearne una tutta nostra.
Parti dal tuo caso d’uso
Se vuoi creare una tua skill personalizzata — e questo è il punto — devi andare a ingegnerizzare e rendere più stabile un comportamento che vuoi dare a un agente, a un chatbot o a uno strumento generalista.
Prima di scrivere qualsiasi codice, identifica due o tre casi d’uso concreti che la tua skill dovrebbe avere.
💡 Per esempio: pianificazione dello sprint di un progetto.
Trigger: quando viene attivata questa skill?
Quando l’utente dice: “Aiutami a pianificare questo sprint” oppure “Crea un task per questo sprint”.
Allora i passaggi potrebbero essere i seguenti:
Recuperare lo stato attuale del progetto dal project management (tipo Linear, eccetera). Questo si può fare tramite un server MCP che collega il modello all’applicazione.
Analizzare la velocità e la capacità del team, andando a prendere questi dati dal project management.
Suggerire priorità dei task.
Creare direttamente i task nel tool.
Quindi chiediti sempre:
Cosa vuole realizzare l’utente?
Quali sono i flussi di lavoro?
Richiede più passaggi?
Ci sono strumenti necessari? Script? Server MCP? Connessioni esterne?
Quali conoscenze o best practice deve proporre la skill?
Queste sono tutte domande da porsi nella prima fase di pianificazione. Serve brainstorming. La skill deve portare a termine un processo come lo faresti a mano.
Cosa serve affinché possa farlo lei?
Tre macro-categorie di Skill
Anthropic, nella guida ufficiale, propone tre tipologie di skill. Sono tre macrocategorie molto chiare da cui puoi prendere ispirazione prima di creare una skill.
1. Creazione di documenti o asset


Skill usate per creare output coerenti e di alta qualità: presentazioni, documenti, front-end.
Un esempio reale è una skill chiamata front-end design, oppure PPTX design per il design di PowerPoint.
Nel caso “front-end design”, la descrizione è più o meno questa:
“Crea interfacce front-end distintive e di livello produttivo, con alta qualità di design. Usata per costruire componenti web, pagine, artefatti, poster o applicazioni.”
Dentro ha:
tecniche di design,
guide di stile,
standard di brand,
template per output coerenti,
checklist di qualità prima della finalizzazione,
controlli di accessibilità (contrasto font/sfondo, ecc.).
Questa categoria è fondamentale per tutte quelle aziende che hanno template standard e vogliono rispettarli.
2. Automatizzazione di flussi
Processi a più fasi che beneficiano di una metodologia coerente e replicabile, magari condivisibile tra colleghi.


Esempio: una skill che guida nella creazione di una nuova skill.
Una meta-skill. Spoiler: esiste già.
Questa skill:
definisce il flusso di lavoro passo passo,
inserisce fasi di validazione,
dice: “Hai scritto l’MD? Quali asset devi aggiungere?”
suggerisce revisioni e miglioramenti,
prevede cicli di affinamento continuo.
Insomma, una skill che guida durante un processo, che può accedere a file, ad applicazioni esterne, e così via.
3. Potenziamento tramite MCP
Terza categoria: skill che migliorano l’accesso a strumenti forniti da server MCP.
Se non sai cosa sono gli MCP, posso farne una guida approfondita.
In breve: sono server che consentono ai modelli di comunicare con applicazioni esterne in modo strutturato.
Esempio.
Voglio che il mio chatbot legga il mio Google Calendar, utilizzo un server MCP collegato a Google Calendar e Il modello interroga l’MCP, prende gli impegni, li mette nel contesto e mi risponde:
“Giovedì non puoi inserire l’appuntamento perché sei dall’osteopata tutto il giorno.”
(Si spera di no.)
La skill qui diventa fondamentale perché definisce:
come usare l’MCP,
quali richieste fare,
quali capacità ha lo strumento,
qual è la metodologia giusta,
qual è il prompt corretto.
Possiamo introiettare tutto questo dentro la skill.
In conclusione
Nella fase iniziale di design questi sono gli interrogativi da porci.
E soprattutto consideriamo queste tre categorie di skill, che sono anche le più frequenti online:
Creazione coerente di asset e documenti.
Automatizzazione di flussi complessi.
Potenziamento tramite strumenti esterni (MCP).
Se ragioniamo così fin dall’inizio, la skill non diventa un semplice file Markdown.
Diventa un modulo operativo strutturato.
Creazione di una Skill
Adesso entriamo un attimo nella parte più tecnica della creazione di una skill.
Niente di trascendentale, però ci sono delle regole precise. E qui non si scappa.
Struttura dei file
La skill è una cartella che deve avere questa struttura:
your-skill-name/
├── SKILL.md # Obbligatorio – file principale della skill
├── scripts/ # Opzionale – codice eseguibile
│ ├── process_data.py
│ └── validate.sh
├── references/ # Opzionale – documentazione
│ ├── api-guide.md
│ └── examples/
└── assets/ # Opzionale – template, risorse, ecc.
└── report-template.mdIl cuore è lo SKILL.md , tutto il resto sono ingredienti.
YAML frontmatter: la parte più importante
Questa è la parte cruciale che è la prima parte del file SKILL.md
Lo YAML frontmatter è il meccanismo con cui Claude decide se caricare o meno la tua skill.
Se sbagli qui, la skill non viene attivata correttamente.
Formato minimo richiesto:
---
name: your-skill-name
description: What it does. Use when user asks to [specific phrases].
---Semplice. Ma deve essere fatto bene.
Regole critiche
A - Nome del file SKILL.md
Deve chiamarsi esattamente
SKILL.mdÈ case-sensitive
Non sono accettate varianti:
- SKILL.MD ❌ - skill.md ❌ - Skill.md ❌
C - Requisiti dei campi nel frontmatter
name (obbligatorio)
Solo kebab-case
Niente spazi
Niente maiuscole
Deve combaciare con il nome della cartella
description (obbligatorio)
Qui molti sbagliano.
La description deve includere entrambe queste cose:
Cosa fa la skill
Quando deve essere usata (condizioni di trigger)
In più:
Deve stare sotto i 1024 caratteri
Non può contenere tag XML (
<o>)Deve includere esempi concreti di task che l’utente potrebbe dire
Se rilevante, menzionare tipi di file
Non è una descrizione generica. È una descrizione operativa.
F - compatibility (opzionale)
Campo da 1 a 500 caratteri.
Serve per indicare requisiti ambientali:
prodotto per cui è pensata
pacchetti di sistema richiesti
necessità di accesso alla rete
dipendenze particolari
B- Nome della cartella della skill
Deve essere in kebab-case.
Esempio corretto: notion-project-setup ✅
Esempio sbagliato: Notion Project Setup ❌
Quindi:
- niente spazi, niente underscore, niente maiuscole
Solo minuscolo e trattini.
E questo è tutto quello che serve per iniziare.
D - README.md – attenzione
Non devi includere un README.md dentro la cartella della skill.
Tutta la documentazione deve stare:
o dentro
SKILL.mdo dentro
references/
Nota: se distribuisci la skill su GitHub, ovviamente puoi avere un README a livello di repository per gli umani. Ma non dentro la cartella della skill stessa.
E - license (opzionale)
Se vuoi rendere la skill open source, puoi aggiungere il campo license.
Le più comuni:
MIT
Apache-2.0
G - metadata (opzionale)
Puoi aggiungere coppie chiave-valore personalizzate.
Campi suggeriti:
author
version
mcp-server
Esempio:
metadata:
author: ProjectHub
version: 1.0.0
mcp-server: projecthubRestrizioni di sicurezza
Nel frontmatter è vietato inserire:
Tag XML con parentesi angolari (
< >)Skill che contengano “claude” o “anthropic” nel nome (nomi riservati)
Perché?
Perché il frontmatter viene inserito nel system prompt e contenuti malevoli potrebbero iniettar istruzioni indesiderate.
Quindi qui bisogna essere rigorosi, questo è il minimo tecnico indispensabile.
Scrivere skills che funzionano bene
Perfetto. Adesso entriamo nella parte fondamentale, e che spesso viene sottovalutata: come si scrive bene una skill.
Non come si crea tecnicamente la cartella. Ma come si scrive in modo efficace. Perché qui si gioca tutto.
1. Il campo description
Partiamo dal campo description , che non è un campo qualsiasi, è il cervello decisionale della skill.
Anthropic nel loro engineering blog dice una cosa molto interessante: questa parte di metadata fornisce “giusto abbastanza informazione” affinché Claude capisca quando usare la skill, senza caricarla tutta nel contesto.
Quindi non è una descrizione marketing, non è una frase generica, è una regola operativa.
La struttura ideale è questa: [Che cosa fa] + [Quando usarla] + [Capacità chiave]
✅ Esempi di buone description
Buona, perché è specifica e azionabile:
description: Analyzes Figma design files and generates developer handoff documentation. Use when user uploads .fig files, asks for "design specs", "component documentation", or "design-to-code handoff".Qui è chiarissimo:
Cosa fa → analizza file Figma e genera documentazione per sviluppatori
Quando usarla → quando l’utente carica .fig o parla di design specs
Linguaggio concreto → parole che un utente direbbe davvero
Altro esempio:
description: Manages Linear project workflows including sprint planning, task creation, and status tracking. Use when user mentions "sprint", "Linear tasks", "project planning", or asks to "create tickets".Qui abbiamo addirittura trigger espliciti: sprint, Linear, create tickets.
Altro esempio ancora:
description: End-to-end customer onboarding workflow for PayFlow. Handles account creation, payment setup, and subscription management. Use when user says "onboard new customer", "set up subscription", or "create PayFlow account".Notate una cosa: c’è sempre la frase “Use when user says…”. Perché? Perché stiamo insegnando al modello a riconoscere pattern linguistici reali.
⛔️ Esempi di cattive description
Troppo vaga:
description: Helps with projects.Aiuta con cosa? Quando? Come? Non dice nulla.
Mancano i trigger:
description: Creates sophisticated multi-page documentation systems.Bello. Ma quando la attivo?
Troppo tecnica, zero orientamento all’utente:
description: Implements the Project entity model with hierarchical relationships.Qui stiamo parlando come un database, non come un utente. La description deve parlare il linguaggio dell’utente, non dell’architetto software.
2. Scrivere le istruzioni principali
Dopo il frontmatter inizia la parte vera.
Lo SKILL.md deve contenere istruzioni scritte in Markdown. E devono essere chiare. Non ambigue. Non implicite.
Una struttura consigliata è questa:
---
name: your-skill
description: [...]
---
# Your Skill Name
## InstructionsPoi iniziano i passi operativi.
Step-by-step chiaro
Esempio:
## Step 1: Fetch project data
Run:
python scripts/fetch_data.py --project-id PROJECT_ID
Expected output:
JSON file containing project tasks and metadata.Notate una cosa.
Non basta scrivere “fetch data”.
Bisogna scrivere:
cosa succede
quale comando viene eseguito
cosa deve produrre
cosa significa successo
Perché la skill non deve interpretare. Deve eseguire.
Sezione Esempi
Questa parte è potentissima.
Qui fate vedere casi concreti.
Esempio:
Example 1: Creating a marketing campaign
User says:
"Set up a new marketing campaign"
Actions:
1. Fetch existing campaigns via MCP
2. Create new campaign with provided parameters
3. Return confirmation link
Result:
Campaign created successfully.Questo serve a due cose:
dare esempi concreti di attivazione
ridurre ambiguità
Se la skill non ha esempi, è molto più fragile.
Sezione Troubleshooting
Qui molti sbagliano.
Non è una formalità.
È la parte che evita che la skill collassi al primo errore.
Struttura semplice:
Error: Connection refused
Cause: MCP server not running
Solution:
1. Verify MCP server is active
2. Check API key
3. Retry connectionNon serve scrivere trattati.
Serve scrivere:
quale errore potresti vedere
perché succede
come lo risolvi
Se la skill usa script di validazione, scrivilo chiaramente:
Run:
python scripts/validate.py --input file.csvSe fallisce, spiegare perché potrebbe fallire:
campi obbligatori mancanti
date in formato sbagliato (usa YYYY-MM-DD)
encoding errato
Questo è design robusto.
Best Practices per scrivere bene
1. Cita le risorse in modo chiaro
Se esiste references/api-patterns.md , scrivilo esplicitamente:
“Before writing queries, consult references/api-patterns.md for rate limiting, pagination, and error handling.”
Non dare per scontato che la skill sappia dove guardare.
2. Sii specifico e pratico
Buono:
“Run python scripts/validate.py --input {filename}”
Non buono:
“Validate the data before proceeding.”
La differenza è enorme.
3. Usa progressive disclosure anche dentro la skill
Non mettere 40 pagine nello SKILL.md tienilo focalizzato sulle istruzioni core.
La documentazione dettagliata spostala in references/ e linkala.
Ricorda: tre livelli.
YAML → quando usarla
SKILL.md → cosa fare
references/scripts/assets → dettagli operativi
4. Includi gestione errori
Esempio:
## Common Issues
### MCP Connection Failed
If you see "Connection refused":
1. Verify MCP server is running (Settings > Extensions)
2. Confirm API key is valid
3. Retry connectionNon aspettare che l’errore succeda in produzione: anticipalo.
💡 Cosa importante da tenere in mente
Scrivere una skill non è scrivere un prompt, è progettare un comportamento.
Se la description è vaga, la skill non si attiva, se le istruzioni sono ambigue, la skill fallisce, se non hai esempi, la skill interpreta male.
Se non hai troubleshooting, la skill si rompe al primo problema.
Una skill ben scritta è quasi noiosa da quanto è chiara.
Testing and Iteration
Qui parliamo di testing e iterazione. Perché una skill non è un file statico. È un comportamento. E i comportamenti si testano.
Le skill possono essere testate con livelli diversi di rigore. Dipende da quanto è critica quella skill e da quante persone la useranno.
Modalità di testing
Abbiamo tre modalità principali.
1. Manual testing in Claude.ai
La più semplice.
Fai query direttamente dentro Claude, osservi il comportamento, vedi se si attiva, vedi cosa fa.
Pro:
Nessun setup.
Iterazione velocissima.
Perfetto per le prime versioni.
Contro:
Non è sistematico.
Non è ripetibile in modo strutturato.
È testing “a occhio”, ma spesso è il primo step giusto.
2. Scripted testing in Claude Code
Qui iniziamo a fare le cose seriamente.
Automatizzi dei casi di test, crei scenari ripetibili.
Ogni volta che modifichi la skill, puoi rieseguire la suite di test e vedere se qualcosa si è rotto.
Questo è fondamentale quando:
la skill è complessa,
usa MCP,
fa chiamate API,
deve essere stabile nel tempo.
3. Programmatic testing via Skills API
Qui siamo nel livello più alto.
Costruisci vere e proprie evaluation suite che girano in modo sistematico su set di test definiti.
Questo è il livello enterprise. Non serve sempre. Ma quando serve, serve.
Scegli in base al contesto
Domanda semplice:
Quanta visibilità ha la tua skill?
Interna, per un piccolo team → testing leggero va bene.
Pubblica, distribuita, enterprise → devi essere rigoroso.
Non è una questione ideologica. È una questione di rischio.
Pro Tip: iterare su un singolo task
I migliori creatori di skill non partono con 50 casi d’uso ma partono con uno.
Uno difficile. Uno reale.Iterano su quello finché Claude non lo fa perfettamente.
Poi prendono quella soluzione vincente e la cristallizzano nella skill.
Questo sfrutta l’in-context learning del modello.
Invece di fare testing largo e superficiale, fai testing profondo su un task.
Quando funziona bene, espandi.
Approccio consigliato al testing
Dalla pratica emergono tre aree chiave.
1️⃣ Triggering Tests
Obiettivo: assicurarti che la skill si attivi quando deve.
Testa:
✅ Si attiva su task ovvi.
✅ Si attiva su richieste parafrasate.
❌ Non si attiva su argomenti non correlati.
Esempio.
Se hai una skill ProjectHub.
Dovrebbe attivarsi su:
“Help me set up a new ProjectHub workspace”
“I need to create a project in ProjectHub”
“Initialize a ProjectHub project for Q4 planning”
Non dovrebbe attivarsi su:
“What’s the weather in San Francisco?”
“Help me write Python code”
“Create a spreadsheet” (a meno che la skill non gestisca fogli)
Qui capisci se hai overtriggering o undertriggering.
2️⃣ Functional Tests
Obiettivo: verificare che la skill faccia correttamente quello che promette.
Testa:
Output valido.
Chiamate API che vanno a buon fine.
Error handling funzionante.
Edge case coperti.
Esempio concreto.
Test: creare progetto con 5 task.
Given:
Nome progetto: “Q4 Planning”
5 descrizioni task
When:
- La skill esegue il workflow
Then:
Il progetto viene creato in ProjectHub
I 5 task vengono creati con le proprietà corrette
Tutti i task sono collegati al progetto
Nessun errore API
Questo è testing serio.
3️⃣ Performance Comparison
Qui la domanda è: la skill migliora davvero qualcosa?
Confronto baseline.
Senza skill:
15 messaggi di botta e risposta
3 chiamate API fallite
12.000 token consumati
Con skill:
Workflow automatico
2 domande chiarificatrici
0 errori API
6.000 token consumati
Se non migliora:
tempo,
stabilità,
consumo di token,
forse non è una buona skill.
Scorciatoia: usare la skill “skill-creator”
Esiste una skill che ti aiuta a creare skill. Sì.
La trovi in Claude.ai come plugin oppure la puoi usare in Claude Code.
Se hai un MCP server e conosci i tuoi 2–3 workflow principali, puoi creare una skill funzionante in una singola sessione. Spesso in 15–30 minuti.
Cosa fa?
Creazione
Genera skill da descrizioni in linguaggio naturale.
Produce uno SKILL.md formattato correttamente.
Suggerisce trigger phrase.
Suggerisce struttura.
Revisione
Segnala descrizioni vaghe.
Evidenzia trigger mancanti.
Individua problemi strutturali.
Ti avvisa se rischi overtriggering o undertriggering.
Iterazione
Se dopo l’uso reale emergono edge case o fallimenti, puoi riportarli dentro skill-creator.
Esempio:
“Usa i problemi emersi in questa chat per migliorare la gestione del caso X.”
Nota importante:
Skill-creator ti aiuta a progettare e migliorare la skill.
Non esegue test quantitativi automatici.
Iterazione basata sul feedback
Le skill sono documenti vivi. Non le scrivi una volta e basta. Devi osservare segnali.
Segnali di Undertriggering
La skill non si attiva quando dovrebbe.
Gli utenti la attivano manualmente.
Ricevi domande tipo “quando devo usarla?”
Soluzione:
Raffina la description.
Aggiungi parole chiave.
Aggiungi più contesto tecnico.
Segnali di Overtriggering
La skill si attiva su richieste irrilevanti.
Gli utenti la disabilitano.
Confusione sul suo scopo.
Soluzione:
Sii più specifico nella description.
Aggiungi trigger negativi.
Restringi il campo semantico.
In conclusione
Testing non è “vedere se funziona”.
Testing è:
capire quando si attiva,
capire se fa quello che deve,
capire se migliora davvero il processo,
capire se consuma meno risorse.
Una skill matura è una skill che è stata iterata.
E iterare significa ascoltare i fallimenti.
Uno standard aperto
Agent Skills è stato pubblicato come standard aperto.
Come MCP, l’idea è che le skill siano portabili tra strumenti e piattaforme.
La stessa skill dovrebbe funzionare su Claude o su altre piattaforme AI.
Certo, alcune skill possono sfruttare funzionalità specifiche di una piattaforma. In quel caso, l’autore può dichiararlo nel campo compatibility .
Ma il principio è questo: portabilità, non lock-in.
Uso delle skill via API
Adesso saliamo di livello. Se stai costruendo applicazioni, agenti personalizzati, workflow automatici… non userai Claude.ai manualmente.
Userai l’API.
L’API ti dà controllo diretto su:
Endpoint
/v1/skillsper listare e gestire skill.Aggiungere skill alle richieste della Messages API tramite il parametro
container.skills.Versioning e gestione tramite Claude Console.
Integrazione con Claude Agent SDK per costruire agenti custom.
Questa è la modalità “programmatica”.
Quando usare API vs Claude.ai?
Domanda semplice.
| Use Case | Superficie consigliata |
|---|---|
| Utenti finali che interagiscono direttamente | Claude.ai / Claude Code |
| Testing manuale durante sviluppo | Claude.ai / Claude Code |
| Workflow individuali ad-hoc | Claude.ai / Claude Code |
| Applicazioni che usano skill programmaticamente | API |
| Deploy in produzione su larga scala | API |
| Pipeline automatiche e sistemi agentici | API |
Se stai facendo prodotto, vai di API.
💡 Nota importante:
Per usare le skill via API serve il Code Execution Tool (beta), che fornisce l’ambiente sicuro necessario all’esecuzione.
Approccio per la gestione delle Skill
Se vuoi distribuire bene una skill, fallo in modo serio.
1️⃣ Host su GitHub
Repo pubblico se open-source.
README chiaro (per umani).
Istruzioni di installazione.
Esempi concreti.
Screenshot.
Nota: il README è a livello repository.
Non dentro la cartella della skill.
2️⃣ Documenta nel tuo MCP Repo
Nel tuo repository MCP:
Metti il link alla skill.
Spiega perché usarle insieme.
Dai una quick-start guide.
Non dare per scontato che l’utente capisca la sinergia.
Spiegagliela.
3️⃣ Crea una guida di installazione chiara
Esempio:
Installing the [Your Service] skill
Download:
git clone https://github.com/yourcompany/skillsoppure scarica lo ZIP da Releases.
Installa in Claude:
Claude.ai > Settings > Skills
Click “Upload skill”
Seleziona la cartella ZIP.
Abilita:
Attiva la skill.
Verifica che l’MCP server sia connesso.
Test:
- Chiedi: “Set up a new project in [Your Service]”
Deve essere impossibile sbagliare.
Patterns and troubleshooting
Qui parliamo di pattern: cioè i modi in cui, nella pratica, le skill vengono scritte bene e funzionano bene. E poi parliamo di troubleshooting: cioè quando non funziona, come la sblocchi senza impazzire.
E attenzione: questi pattern non sono “template obbligatori”. Sono cose emerse da early adopters e team interni. Quindi sono approcci che si sono visti funzionare spesso, non dogmi.
Scegliere l’approccio: problem-first vs tool-first
Qui c’è una metafora che mi piace un sacco: Brico
Tu puoi entrare in due modi.
Modo 1: entri con un problema.
“Devo aggiustare un’anta della cucina.”
E il commesso ti dice: “Ok, ti servono questi strumenti.”
Modo 2: entri perché hai visto un trapano nuovo.
“Ho comprato questo trapano. Come lo uso per fare X?”
Le skill funzionano uguale.
🔹 Problem-first
“I need to set up a project workspace” → la skill orchestra le chiamate MCP giuste, nel giusto ordine.
L’utente descrive un risultato. La skill gestisce gli strumenti.
Tradotto: l’utente parla per obiettivi, la skill fa da regista.
🔹 Tool-first
“I have Notion MCP connected” → la skill insegna a Claude i workflow ottimali e le best practice.
L’utente ha già accesso allo strumento. La skill aggiunge competenza.
Tradotto: l’utente dice “ho questo tool”, la skill dice “ok, ecco come usarlo bene, in modo professionale”.
Molte skill pendono chiaramente da una parte.
Capire quale framing è giusto per il tuo caso ti aiuta a scegliere il pattern corretto.
Pattern 1: Sequential workflow orchestration
Quando usarlo: quando gli utenti hanno processi multi-step che devono avvenire in un ordine preciso.
Esempio classico: onboarding di un nuovo cliente.
Workflow: Onboard New Customer
Step 1: Create Account
Call MCP tool:
create_customerParametri: name, email, company
Step 2: Setup Payment
Call MCP tool:
setup_payment_methodWait for: verifica del metodo di pagamento
Step 3: Create Subscription
Call MCP tool:
create_subscriptionParametri: plan_id, customer_id (che ti porti dietro dallo Step 1)
Step 4: Send Welcome Email
Call MCP tool:
send_emailTemplate: welcome_email_template
Tecniche chiave:
ordine esplicito dei passi (non “poi fai questo”, proprio Step 1, Step 2…)
dipendenze tra step (customer_id nasce nello Step 1, serve nello Step 3)
validazione ad ogni stadio
rollback se fallisce qualcosa (se hai creato account ma fallisce pagamento, cosa fai? annulli? segnali? metti in pending?)
Pattern 2: Multi-MCP coordination
Quando usarlo: quando il workflow attraversa più servizi.
Esempio: handoff design → sviluppo.
Design-to-development handoff
Phase 1: Design Export (Figma MCP)
Esporta asset da Figma
Genera design specs
Crea un manifest degli asset
Phase 2: Asset Storage (Drive MCP)
Crea cartella progetto in Drive
Upload di tutti gli asset
Genera link condivisibili
Phase 3: Task Creation (Linear MCP)
Crea task di sviluppo
Attacca link degli asset ai task
Assegna al team engineering
Phase 4: Notification (Slack MCP)
Posta un riepilogo in #engineering
Include link asset e riferimenti ai task
Tecniche chiave:
separazione chiara per fasi (non un blob unico)
passaggio dati tra MCP (es: link Drive che finisce dentro Linear)
validazione prima di passare alla fase successiva
error handling centralizzato (non error handling “spezzettato” ovunque)
Pattern 3: Iterative refinement
Quando usarlo: quando la qualità migliora con iterazioni successive.
Esempio: generazione report.
Iterative Report Creation
Initial Draft
Fetch data via MCP
Genera prima bozza del report
Salva in file temporaneo
Quality Check
Run validation script:
scripts/check_report.pyIdentifica problemi:
sezioni mancanti
formattazione incoerente
errori di validazione dati
Refinement Loop
Risolvi ogni issue identificata
Rigenera solo le sezioni impattate
Re-validate
Ripeti finché non raggiungi la soglia qualità
Finalization
Applica formattazione finale
Genera summary
Salva versione finale
Tecniche chiave:
criteri di qualità espliciti (se non li scrivi, l’AI “si accontenta”)
iterazione guidata, non casuale
script di validazione (dove possibile)
sapere quando fermarsi (sennò loop infinito: “migliora ancora”)
Pattern 4: Context-aware tool selection
Quando usarlo: stesso obiettivo, strumenti diversi in base al contesto.
Esempio: storage file.
Smart File Storage
Decision Tree
Controlla tipo e dimensione file
Decide dove salvarlo:
file grandi (>10MB): cloud storage MCP
documenti collaborativi: Notion/Docs MCP
file di codice: GitHub MCP
file temporanei: local storage
Execute Storage
chiama il tool MCP appropriato
applica metadata specifici del servizio
genera link di accesso
Provide Context to User
- spiega perché hai scelto quello storage
Tecniche chiave:
criteri decisionali espliciti
fallback (se Drive è giù, dove vai?)
trasparenza: “ho scelto X per questi motivi”
Pattern 5: Domain-specific intelligence
Quando usarlo: quando la skill aggiunge conoscenza specialistica oltre il semplice “accesso al tool”.
Esempio: compliance finanziaria.
Payment Processing with Compliance
Before Processing (Compliance Check)
Fetch dettagli transazione via MCP
Applica regole:
controlla liste sanzioni
verifica giurisdizioni consentite
valuta rischio
Documenta decisione di compliance
Processing
IF compliance passed:
chiama MCP pagamenti
applica fraud checks
processa transazione
ELSE:
flag per review
crea case di compliance
Audit Trail
log di tutti i controlli
record decisioni
genera audit report
Tecniche chiave:
domain expertise dentro la logica
compliance prima dell’azione
documentazione completa
governance chiara
Troubleshooting
Ok, adesso la parte pratica: quando va male.
Skill won’t upload
Errore: “Could not find SKILL.md in uploaded folder”
Causa: il file non si chiama esattamente SKILL.md
Soluzione:
rinomina in
SKILL.md(case-sensitive)verifica con
ls -lache esista davveroSKILL.md
Errore: “Invalid frontmatter”
Causa: YAML scritto male.
Errori comuni:
❌ sbagliato, mancano i delimitatori:
name: my-skill
description: Does things❌ sbagliato, virgolette non chiuse:
---
name: my-skill
description: "Does things
---✅ corretto:
---
name: my-skill
description: Does things
---Errore: “Invalid skill name”
Causa: nome con spazi o maiuscole.
❌
name: My Cool Skill✅
name: my-cool-skillSkill doesn’t trigger
Sintomo: la skill non si carica mai in automatico.
Fix: quasi sempre è la description .
Checklist rapidissima:
è troppo generica? (“Helps with projects” non funzionerà mai)
include trigger phrase che un utente direbbe davvero?
menziona tipi di file se rilevante?
Debug facile:
Chiedi a Claude: “Quando useresti la skill [nome skill]?”
Claude ti citerà la description.
Tu la guardi e dici: “ok, cosa manca? cosa è troppo vago?”
Skill triggers too often
Sintomo: si attiva su richieste irrilevanti.
Soluzione 1: aggiungi negative triggers.
Esempio:
“Do NOT use for simple data exploration (use data-viz skill instead).”
Soluzione 2: sii più specifico.
Troppo broad:
“Processes documents”
Più specifico:
“Processes PDF legal documents for contract review”
Soluzione 3: chiarisci lo scope.
Esempio:
“PayFlow payment processing for e-commerce… not for general financial queries.”
MCP connection issues
Sintomo: la skill si carica, ma le chiamate MCP falliscono.
Checklist:
- MCP server connesso?
Claude.ai: Settings > Extensions > [Your Service]
deve dire “Connected”
- Autenticazione ok?
API key valida e non scaduta
permessi/scopes giusti
OAuth token refreshato
Test MCP indipendente
Chiedi a Claude (senza skill):
“Use [Service] MCP to fetch my projects”
Se fallisce, il problema è MCP, non skill.
Tool names corretti
i nomi sono case-sensitive
la skill deve referenziare esattamente quei tool
controlla doc del server MCP
Instructions not followed
Sintomo: la skill si carica, ma Claude non segue davvero le istruzioni.
Cause comuni:
- istruzioni troppo verbose
tienile concise
bullet point e numeri
dettagli in references/
- istruzioni “sepolte”
metti le cose critiche all’inizio
usa header tipo “## Important” o “## Critical”
ripeti i punti chiave se serve
- linguaggio ambiguo
❌ “Make sure to validate things properly”
✅ “CRITICAL: Before calling create_project, verify:
project name non vuoto
almeno un membro assegnato
start date non nel passato”
Tecnica avanzata:
se la validazione è critica, meglio uno script che controlla davvero.
Il codice è deterministico. Il linguaggio è interpretazione.
“laziness” del modello
A volte serve un rinforzo:
“Take your time. Quality > speed. Do not skip validation.”
Nota: spesso funziona meglio inserirlo nei prompt utente, non nello SKILL.md.
Large context issues
Sintomo: skill lenta o risposte degradate.
Cause:
contenuto skill troppo grande
troppe skill abilitate insieme
carichi tutto invece di progressive disclosure
Soluzioni:
- ottimizza SKILL.md
sposta documentazione in references/
linka invece di incollare
tienilo sotto ~5.000 parole
- riduci skill abilitate
se ne hai 20–50 tutte insieme, è tanto
meglio abilitazione selettiva
considera “skill pack” per set di capability correlate
Il takeaway
Questa sezione, secondo me, ti dà proprio l’idea che le skill non sono “una cartella con un file”. Sono un modo di progettare comportamenti robusti.
E quando qualcosa va storto, non devi “pregare”.
Hai pattern. Hai checklist. Hai troubleshooting.
E questo è quello che fa la differenza tra una skill che funziona una volta… e una skill che funziona sempre.
Conclusione: le Skills e gli otto pilastri che cambiano il paradigma
Ora facciamo un ultimo paragrafo a fondo, in cui andiamo a definire in maniera conclusiva questo percorso sulle skills e sugli otto pilastri da tenere in considerazione, che cambiano proprio il paradigma del modo in cui noi usiamo questi strumenti di intelligenza artificiale.
Abbiamo visto che le skills non sono una nuova feature messa lì tanto per. Sono un cambio di paradigma importante.
A mio avviso questa parte finale è la più importante per i meno tecnici che vogliono solo una visione d’insieme, ma è importante anche per i tecnici. Perché questi otto pilastri impattano davvero l’avvento delle skills, e ti fanno capire perché questa cosa è grossa.
1) Una skill è un’unità di affidabilità
Questo è il primo pilastro.
Nel mondo del lavoro — soprattutto enterprise, ma anche PMI e liberi professionisti — quello che vogliamo è l’output ripetibile. Punto.
E siccome stiamo usando una tecnologia non deterministica, tutto ciò che ci aiuta a ottenere un output più deterministico, più controllato, più seguito e più standardizzato… è un bene.
Le skills permettono di codificare procedure.
Stessi input → stessi step → più o meno lo stesso output.
Quindi il primo paradigma è questo: le skills spingono verso un mondo dove il non determinismo viene governato tramite binari, tramite linee guida, tramite un comportamento che porta il modello dove vogliamo noi.
2) Una skill è disciplina di contesto e budgeting
Secondo pilastro.
Le skills incarnano il pattern del progressive disclosure: carichi solo ciò che serve, metti solo ciò che serve, nel momento in cui serve.
E questo fa due cose:
ti aumenta la qualità dell’output, perché non stai sporcando il contesto con roba inutile
ti migliora il budgeting del contesto, perché usi token in modo intelligente
Quindi “più contesto” non è sempre meglio.
“Contesto giusto” è meglio.
3) Una skill è un router mentale
Terzo pilastro.
Quando creiamo skill, in realtà stiamo facendo anche chiarezza mentale su quello che ci interessa davvero far portare a termine a questi strumenti.
Lo YAML frontmatter è un sistema di routing: istrada il modello verso comportamenti che io posso controllare, posso versionare, posso gestire.
E come abbiamo visto, posso gestirli:
a livello personale
a livello di organizzazione
Quindi non è solo “trigger tecnico”. È proprio una forma di architettura del comportamento.
4) Standardizzazione della qualità
Quarto pilastro.
Senza skills ogni utente prompta a modo suo.
In un piccolo team ok, ti arrangi.
In un team grande o in un’organizzazione, diventa un caos.
Con le skills puoi uniformare e standardizzare i processi.
Ed è una cosa enorme.
Perché riduci la variabilità tra persone, tra reparti, tra giorni diversi, tra “oggi sono stanco” e “oggi sono lucido”.
Questo è standard di qualità applicato all’AI.
5) Ponte tra tool esterni e intelligenza artificiale
Quinto pilastro.
Quando la gente usa tool esterni — server MCP, function call, software esterni da cui prendere dati — una skill può definire:
quando chiamare quel tool
che parametri usare
come verificarne l’output
se e come restituire un output strutturato
Questo si sposa con la spinta generale: semplificare l’interazione tra applicazioni esterne e strumenti AI.
Quindi la skill diventa il collante tra “accesso agli strumenti” e “metodologia di utilizzo”.
6) Modulo di onboarding per umani e agenti
Sesto pilastro.
Una skill non è solo una skill. È anche documentazione viva.
Ti permette di proceduralizzare qualcosa che è utile a te, al team, all’azienda.
Ti crea chiarezza mentale.
Ti crea un modo di lavorare condivisibile.
È la metafora della ricetta: non è solo “fai la pasta”. È come la facciamo qui dentro.
E questa cosa la puoi standardizzare e condividere con tutta l’azienda.
7) Anti-saturazione del contesto
Settimo pilastro.
In sistemi agentici e chatbot è facilissimo intasare il contesto con mille informazioni:
alcune utili
alcune inutili
alcune addirittura dannose
E perché le dobbiamo mettere?
Sprechiamo soldi, sprechiamo tempo, degradiamo performance.
Le skills sono uno strumento per pulire il contesto.
E ricordiamoci che in un mondo dove il context engineering sta diventando un po’ il re di tutto, gestire il contesto è importantissimo.
8) Versioning e governance
Ottavo pilastro.
Grazie alle skills, un’azienda (anche piccola) può fare governance su processi e strumenti, e su come si utilizza l’intelligenza artificiale.
Non tutti devono essere esperti di prompt engineering.
Alcuni possono semplicemente attivare la skill e usufruire della competenza di poche persone in azienda che fanno questo lavoro: progettare le skill, mantenerle, migliorarle.
Quindi le skill diventano “conoscenza operativa versionata”.
Ed è un salto culturale.
Conclusione
Le skills sono uno strumento che è qui per restare.
Non è hype.
È innovazione di processo. Ed è una cosa che vi invito davvero a esplorare.
I passi che vi invito a fare sono questi:
Scaricate skill fatte da altri.
Testatele, guardatele, portatele al limite.
Scaricatene quante più possibile, così vedete la differenza tra una skill e l’altra, cosa cambia, cosa funziona, cosa no.
Poi iniziate a farne una vostra, anche piccola, anche stupida, anche “semplice semplice”, ma che vi serve davvero.
Perché il vero salto non è “sapere cosa sono le skill”.
È iniziare a ragionare così: il contesto non si spreca. Si progetta.